Notes on object storage architecture from Haystack paper
Facebook traditional storage system serving photos was build using NFS served by NAS servers. This system was not scaling well and was not able to handle the load. File system metadata was determined as one of major bottlenecks of the system. First because of speed: each file read incurs metadata read first and then data read. Secondly because space is wasted on metadata - for example permissions are irrelevant in their use-case. Additionally, they have noticed that usage pattern for photos on Facebook is harder to optimize via CDN due to long-tail characteristics.
Let’s dive into details of Haystack architecture based on Finding a needle in Haystack: Facebook’s photo storage - Meta Research paper from 2010 and see what we can learn from it.
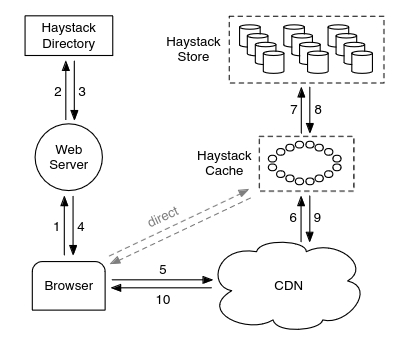
Haystack consists of three main components:
- Store - encapsulates the persistent storage system and manages the filesystem metadata.
- Directory - maintains logical to physical mapping along with other application metadata like how much free space there is in given volume and more importantly it’s responsible for load balancing writes and reads across machines and volumes.
- Cache - caches data from Store and function as fallback for CDN
Haystack Directory service
Pretty straightforward service with replicated database and memcached for caching. It is responsible for:
- Maps from logical volume ID to physical volume ID
- Performs write and read load balancing across logical volumes and physical volumes
- Determines whether request should be served by CDN or Haystack Cache
- Identifies read-only volumes either due to operational issues or due to volume being full
Web server uses Haystack Directory to construct URL in form of:
http://<CDN>/<Cache>/<Machine_ID>/<Logical volume_ID>,<photo_ID>
What is pretty neat about it is that if CDN does not have resource <Logical volume_ID>,<photo_ID> it tries to fetch it from cache via http://<Cache>/<Machine_ID>/<Logical volume_ID>,<photo_ID> and so there is no need to map resource to URL again since all you need is already in the URL. If file is not there then cache tries to fetch from http://<Machine_ID>/<Logical volume_ID>,<photo_ID>. Bypassing CDN and going straight to cache is also very easy to implement.
Haystack Cache
Organized as distributed hash table. It’s capable of serving requests from CDN or directly from web browsers. It caches requests:
- coming directly from user - because if request misses CDN then it’s unlikely that internal cache will have it
- directed towards write-enabled volumes - because file is requested soon after it’s written so this is the way to shelter write-enabled volumes from additional read load
Haystack Store
Haystack Store consist of multiple machines. Each machine manages multiple (around 100) logical volumes. Each logical volume maps into multiple - typically three - physical volumes or replicas.
Each logical volume is a single file, say /hay/haystack_<logical_volume_id>. XFS is used as underlying file system thanks to small size of blockmaps for large files and files preallocation (which counteracts fragmentation). Machine can access file by having logical volume ID and file offset at which file data resides. Disk operations are minimized by loading mapping (so-called needle) of key, alternate key to flags, size, volume offset at the application startup phase and keeping it in memory. It’s worth to mention that file descriptors for volume files are constantly open. This approach allows to bypass metadata operations of underlying file system and lays ground for sequential reads and writes.
Store supports three operations: read, write and delete. So basically volume it a big file with files appended one after another. Additionally, each file is encapsulated with metadata structure (called needle) and in order to speed up access key-value store sits on top of it. All of these steps optimize access to the file pushing disk operations to the minimum.
Haystack has fault tolerance to disk by using RAID-6 (effective-replication-factor 1.2). Volumes are placed on different racks within primary datacenter, and so they are protected from rack failure and host failure. Datacenter failure is handled by replicating data to secondary datacenter. This gives good fault tolerance at cost of effective-replication-factor of 3.6.1
Read
Read operation is pretty straightforward. File key is mapped to metadata structure and if file was not deleted then data is read from offset up to offset + size. Then cookie field is verified in order to eliminate guessing attacks. Then data checksum is verified and data is returned to the client.
Write
Write appends file to the end of the physical volume and updates in-memory mappings. This leads to need of handling overwrites somehow:
- If file is written to a different logical volume than the original one then Directory overwrite its metadata and original file is never going to be fetched again
- If file is written to the same logical volume then it’s appended to the end of the physical volume as usual but Store will skip original file and use the latest version (based on offset value)
Delete
Deletion request changes in-memory mapping flag and synchronizes it with volume file so it’s kind of soft deletion which is going to be followed by compaction step later on.
Index file
Since Haystack store uses in-memory mapping between key, alternate key and flags, size, volume offset this information needs to be loaded on machine startup by reading all metadata from local volumes. In order to speed up store startup index file is introduced which can be understood as dump of key-value store used to map file key to file offset. Unfortunately index files are updated asynchronously and so two cases are possible:
- orphaned needle: there is needle in the logical volume but not in the index file
- file was marked as deleted but index file was not updated yet - in this case file is going to be found despite it should not
First case is handled by traversing logical volume from the last needle to the first one and if needle is not found in the index file then it’s added and when it’s found then index is up-to-date in terms of orphaned needles. Second case is handled by checking if needle is marked as deleted on read and if so then error is returned and in-memory mapping is updated.
Recovery from failures
- Detection, subsystem called pitchfork performs healthcheck for each machine and volume and if it detects failure then it marks all volumes on the machine as read-only and raises alert.
- Repair, if volume needs repair then bulk sync procedure of recovering volume from replica starts - it’s taking long time because of machine NIC throughput though.
Things that grabbed my attention
- Metadata size was minimized by introducing volumes on top of XFS with custom metadata structure called needle. Some inspirations have been taken from [8] GFS, OBFS. Thanks to needle structure each photo needs 10 bytes per file (times 4 since they keep 4 sizes of the same photo: thumbnail, small, medium, large) which is 40 bytes per photo - pretty good compared to 536 bytes required by XFS xfs_inode_t structure for each file.
- Haystack is designed to maximize IOPS and throughput. IOPS are maximized by keeping metadata in-memory key/value store, load-balancing of write load, shielding write-enabled volumes from reads by using cache, keeping file descriptors to volume files constantly open.
- Compaction reclaims space from deleted and/or duplicated needles by creating new volume file and swapping it with the old when all needles get copied. Insight: 25% of photos gets deleted over course of one year.
- They can handle batch uploads and surprisingly users are importing whole albums often.
- Haystack Directory and Store are modeled after File and Storage Manager concepts from NASD (Network-Attached Secure Disks) project. Haystack takes from log-structured file systems designed to optimize write throughput with the idea that most reads could be served out of cache.
- Bunch of interesting references landing on my to-read list
References
| No. | Citation | Abstract |
|---|---|---|
| 23 | M. Rosenblum and J. K. Ousterhout. The design and implemen- tation of a log-structured file system. ACM Trans. Comput. Syst., 10(1):26–52, 1992 | This paper presents a new technique for disk storage management called a log-structured file system, A log-structured file system writes all modifications to disk sequentially in a log-like structure, thereby speeding up both file writing and crash recovery. The log is the only structure on disk; it contains indexing information so that files can be read back from the log efficiently. In order to maintain large free areas on disk for fast writing, we divide the log into segments and use a segment cleaner to compress the live information from heavily fragmented segments. We present a series of simulations that demonstrate the efficiency of a simple cleaning policy based on cost and benefit. We have implemented a prototype logstructured file system called Sprite LFS; it outperforms current Unix file systems by an order of magnitude for small-file writes while matching or exceeding Unix performance for reads and large writes. Even when the overhead for cleaning is included, Sprite LFS can use 70% of the disk bandwidth for writing, whereas Unix file systems typically can use only 5 – 10%. |
| 19 | S. J. Mullender and A. S. Tanenbaum. Immediate files. Softw. Pract. Exper., 14(4):365–368, 1984. | An efficient disk organization is proposed. The basic idea is to store the first part of the file in the index (inode) block, instead of just storing pointers there. Empirical data are presented to show that this method offers better performance under certain circumstances than traditional methods. |
| 8 | G. R. Ganger and M. F. Kaashoek. Embedded inodes and ex- plicit grouping: exploiting disk bandwidth for small files. In ATEC ’97: Proceedings of the annual conference on USENIX Annual Technical Conference, pages 1–1, Berkeley, CA, USA, 1997. USENIX Association. | Small file performance in most file systems is limited by slowly improving disk access times, even though current file systems improve on-disk locality by allocating related data objects in the same general region. The key insight for why current file systems perform poorly is that locality is insufficient - exploiting disk bandwidth for small data objects requires that they be placed adjacently. We describe C-FSS (Co-locating Fast File System), which introduces two techniques, embedded inodes and explicit grouping, for exploiting what disks do well (bulk data movement) to avoid what they do poorly (reposition to new locations). With embedded inodes, the inodes for most files are stored in the directory with the corresponding name, removing a physical level of indirection without sacrificing the logical level of indirection. With explicit grouping, the data blocks of multiple small files named by a given directory are allocated adjacently and moved to and from the disk as a unit in most cases. Measurement for our C-FSS implementation show that embedded inodes and explicit grouping have the potential to increase small file throughput (for both reads and writes) by a factor of 5-7 compared to the same file system without these techniques. The improvement comes directly from reducing the number of disk accesses required by an order of magnitude. Preliminary experience with software-development applications shows performance improvements ranging from 30-300 percent. |
| 28 | Z. Zhang and K. Ghose. hfs: a hybrid file system prototype for improving small file and metadata performance. SIGOPS Oper. Syst. Rev., 41(3):175–187, 2007 | Two oft-cited file systems, the Fast File System (FFS) and the Log-Structured File System (LFS), adopt two sharply different update strategies—update-in-place and update-out-of-place. This paper introduces the design and implementation of a hybrid file system called hFS, which combines the strengths of FFS and LFS while avoiding their weaknesses. This is accomplished by distributing file system data into two partitions based on their size and type. In hFS, data blocks of large regular files are stored in a data partition arranged in a FFS-like fashion, while metadata and small files are stored in a separate log partition organized in the spirit of LFS but without incurring any cleaning overhead. This segregation makes it possible to use more appropriate layouts for different data than would otherwise be possible. In particular, hFS has the ability to perform clustered I/O on all kinds of data—including small files, metadata, and large files. We have implemented a prototype of hFS on FreeBSD and have compared its performance against three file systems, including FFS with Soft Updates, a port of NetBSD’s LFS, and our lightweight journaling file system called yFS. Results on a number of benchmarks show that hFS has excellent small file and metadata performance. For example, hFS beats FFS with Soft Updates in the range from 53% to 63% in the PostMark benchmark. |
| 10 | G. A. Gibson, D. F. Nagle, K. Amiri, J. Butler, F. W. Chang, H. Gobioff, C. Hardin, E. Riedel, D. Rochberg, and J. Zelenka. A cost-effective, high-bandwidth storage architecture. SIGOPS Oper. Syst. Rev., 32(5):92–103, 1998. | This paper describes the Network-Attached Secure Disk (NASD) storage architecture, prototype implementations of NASD drives, array management for our architecture, and three filesystems built on our prototype. NASD provides scal- able storage bandwidth without the cost of servers used primarily for transferring data from peripheral networks (e.g. SCSI) to client networks (e.g. ethernet). Increasing dataset sizes, new attachment technologies, the convergence of peripheral and interprocessor switched networks, and the increased availability of on-drive transistors motivate and enable this new architecture. NASD is based on four main principles: direct transfer to clients, secure interfaces via cryptographic support, asynchronous non-critical-path oversight, and variably-sized data objects. Measurements of our prototype system show that these services can be cost- effectively integrated into a next generation disk drive ASIC. End-to-end measurements of our prototype drive and filesys- tems suggest that NASD can support conventional distrib- uted filesystems without performance degradation. More importantly, we show scalable bandwidth for NASD-special- ized filesystems. Using a parallel data mining application, NASD drives deliver a linear scaling of 6.2 MB/s per client- drive pair, tested with up to eight pairs in our lab |
| 25 | F. Wang, S. A. Brandt, E. L. Miller, and D. D. E. Long. Obfs: A file system for object-based storage devices. In In Proceedings of the 21st IEEE / 12TH NASA Goddard Conference on Mass Storage Systems and Technologies, pages 283–300, 2004. | The object-based storage model, in which files are made up of one or more data objects stored on self-contained Object-Based Storage Devices (OSDs), is emerging as an architecture for distributed storage systems. The workload presented to the OSDs will be quite different from that of generalpurpose file systems, yet many distributed file systems employ general-purpose file systems as their underlying file system. We present OBFS, a small and highly efficient file system designed for use in OSDs. Our experiments show that our user-level implementation of OBFS outperforms Linux Ext2 and Ext3 by a factor of two or three, and while OBFS is 1/25 the size of XFS, it provides only slightly lower read performance and 10%–40% higher write performance. |
| 26 | S. A. Weil, S. A. Brandt, E. L. Miller, D. D. E. Long, and C. Maltzahn. Ceph: a scalable, high-performance distributed file system. In OSDI ’06: Proceedings of the 7th symposium on Operating systems design and implementation, pages 307–320, Berkeley, CA, USA, 2006. USENIX Association. | We have developed Ceph, a distributed file system that provides excellent performance, reliability, and scala- bility. Ceph maximizes the separation between data and metadata management by replacing allocation ta- bles with a pseudo-random data distribution function (CRUSH) designed for heterogeneous and dynamic clus- ters of unreliable object storage devices (OSDs). We leverage device intelligence by distributing data replica- tion, failure detection and recovery to semi-autonomous OSDs running a specialized local object file system. A dynamic distributed metadata cluster provides extremely efficient metadata management and seamlessly adapts to a wide range of general purpose and scientific comput- ing file system workloads. Performance measurements under a variety of workloads show that Ceph has ex- cellent I/O performance and scalable metadata manage- ment, supporting more than 250,000 metadata operations per second |
| 27 | S. A. Weil, K. T. Pollack, S. A. Brandt, and E. L. Miller. Dy- namic metadata management for petabyte-scale file systems. In SC ’04: Proceedings of the 2004 ACM/IEEE conference on Su- percomputing, page 4, Washington, DC, USA, 2004. IEEE Computer Society. | In petabyte-scale distributed file systems that decouple read and write from metadata operations, behavior of the metadata server cluster will be critical to overall system performance and scalability. We present a dynamic subtree partitioning and adaptive metadata management system designed to efficiently manage hierarchical metadata workloads that evolve over time. We examine the relative merits of our approach in the context of traditional workload partitioning strategies, and demonstrate the performance, scalability and adaptability advantages in a simulation environment. |
| 13 | J. Hendricks, R. R. Sambasivan, S. Sinnamohideen, and G. R. Ganger. Improving small file performance in object-based storage. Technical Report 06-104, Parallel Data Laboratory, Carnegie Mellon University, 2006. | This paper proposes architectural refinements, server-driven metadata prefetching, and namespace flattening for improving the efficiency of small file workloads in object-based storage systems. Server-driven metadata prefetching consists of having the metadata server provide information and capabilities for multiple objects, rather than just one, in response to each lookup. Doing so allows clients to access the contents of many small files for each metadata server interaction, reducing access latency and metadata server load. Namespace flattening encodes the directory hierarchy into object IDs such that namespace locality translates to object ID similarity. Doing so exposes namespace relationships among objects e.g., as hints to storage devices, improves locality in metadata indices, and enables use of ranges for exploiting them. Trace-driven simulations and experiments with a prototype implementation show significant performance benefits for small file workloads. |
| 14 | E. K. Lee and C. A. Thekkath. Petal: distributed virtual disks. In ASPLOS-VII: Proceedings of the seventh international confer- ence on Architectural support for programming languages and operating systems, pages 84–92, New York, NY, USA, 1996. ACM. | The ideal storage system is globally accessible, always available, provides unlimited performance and capacity for a large number of clients, and requires no management. This paper describes the design, implementation, and performance of Petal, a system that attempts to approximate this ideal in practice through a novel combination of features. Petal consists of a collection of network-connected servers that cooperatively manage a pool of physical disks. To a Petal client, this collection appears as a highly available block-level storage system that provides large abstract containers called virtual disks. A virtual disk is globally accessible to all Petal clients on the network. A client can create a virtual disk on demand to tap the entire capacity and performance of the underlying physical resources. Furthermore, additional resources, such as servers and disks, can be automatically incorporated into Petal.We have an initial Petal prototype consisting of four 225 MHz DEC 3000/700 workstations running Digital Unix and connected by a 155 Mbit/s ATM network. The prototype provides clients with virtual disks that tolerate and recover from disk, server, and network failures. Latency is comparable to a locally attached disk, and throughput scales with the number of servers. The prototype can achieve I/O rates of up to 3150 requests/sec and bandwidth up to 43.1 Mbytes/sec. |
| 15 | A. W. Leung, M. Shao, T. Bisson, S. Pasupathy, and E. L. Miller. Spyglass: fast, scalable metadata search for large-scale storage systems. In FAST ’09: Proccedings of the 7th conference on File and storage technologies, pages 153–166, Berkeley, CA, USA, 2009. USENIX Association | The scale of today’s storage systems has made it increasingly difficult to find and manage files. To address this, we have developed Spyglass, a file metadata search system that is specially designed for large-scale storage systems. Using an optimized design, guided by an analysis of real-world metadata traces and a user study, Spyglass allows fast, complex searches over file metadata to help users and administrators better understand and manage their files. Spyglass achieves fast, scalable performance through the use of several novel metadata search techniques that exploit metadata search properties. Flexible index control is provided by an index partitioning mechanism that leverages namespace locality. Signature files are used to significantly reduce a query’s search space, improving performance and scalability. Snapshot-based metadata collection allows incremental crawling of only modified files. A novel index versioning mechanism provides both fast index updates and “back-in-time” search of metadata. An evaluation of our Spyglass prototype using our real-world, large-scale metadata traces shows search performance that is 1-4 orders of magnitude faster than existing solutions. The Spyglass index can quickly be updated and typically requires less than 0.1% of disk space. Additionally, metadata collection is up to 10× faster than existing approaches. |
| 16 | . MacCormick, N. Murphy, M. Najork, C. A. Thekkath, and L. Zhou. Boxwood: abstractions as the foundation for storage infrastructure. In OSDI’04: Proceedings of the 6th conference on Symposium on Opearting Systems Design & Implementation, pages 8–8, Berkeley, CA, USA, 2004. USENIX Association. | Writers of complex storage applications such as distributed file systems and databases are faced with the challenges of building complex abstractions over simple storage devices like disks. These challenges are exacerbated due to the additional requirements for fault-tolerance and scaling. This paper explores the premise that high-level, fault-tolerant abstractions supported directly by the storage infrastructure can ameliorate these problems. We have built a system called Boxwood to explore the feasibility and utility of providing high-level abstractions or data structures as the fundamental storage infrastructure. Boxwood currently runs on a small cluster of eight machines. The Boxwood abstractions perform very close to the limits imposed by the processor, disk, and the native networking subsystem. Using these abstractions directly, we have implemented an NFSv2 file service that demonstrates the promise of our approach. |
Changelog

This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.